
Задача оптимального распределения капитальных вложений в предприятия
На развитие трёх предприятий выделено 5 млн. руб. Известны эффективности вложений в каждое предприятие, заданные значениями нелинейных функций 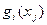 , представленных в следующей таблице:
, представленных в следующей таблице:
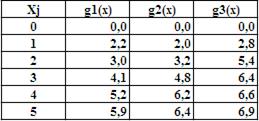
Графические представления функций показаны на Рис.1.
Рис.1. Графические представления функций эффективности.
Расчёты проведём в предположении, что распределение средств осуществляется в целых числах 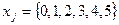 млн. руб.
млн. руб.
Поставленная задача может быть решена тремя способами:
· методом перебора;
· с помощью средства «Поиск решения»;
· методом динамического программирования.
Метод перебора. Применение данного метода оправдывается тем, задача решается в целых числах с малым диапазоном значений переменных. В данном случае три переменные x1, x2 и x3 принимают одно из шести возможных значений: . Следовательно, всего существует  комбинаций переменных. При этом из них для рассмотрения нужно отобрать только те, на которых
комбинаций переменных. При этом из них для рассмотрения нужно отобрать только те, на которых  .
.
Исходные данные занесены на рабочий лист приложения MS Excel, как показано на Рис.2.

Рис.2. Организация исходных данных на рабочем листе.
Для систематического перебора всех комбинаций рационально перевести десятичные числа в диапазоне от 0 до 215 в шестеричную систему счисления. Отдельные разряды шестеричного представления и будут значениями искомых переменных.
Возможный вариант перевода десятичных номеров комбинаций в разряды шестеричного кода представлен на Рис.3.

Рис.3. Формулы перевода десятичных номеров комбинаций в шестеричный код.
Расчёт эффективности вложений выполнен в столбце g1 g2 g3. Для этого в ячейку E14 введена формула:
=ЕСЛИ(B14 C14 D14=5;ПРОСМОТР(B14;$B$3:$B$8;$C$3:$C$8) ПРОСМОТР(C14;$B$3:$B$8;$D$3:$D$8) ПРОСМОТР(D14;$B$3:$B$8;$E$3:$E$8);0), которая затем распространена (протянута) до нижней части таблицы (Рис.4).

Рис.4. Формулы расчёта общей эффективности с учётом ограничений на переменные x1, x2 и x3.
Для выбора оптимального решения в ячейку F14 введена формула выбора максимального значения из всего диапазона вариантов, а ячейки G14, H14 и I14 введены формулы выбора из диапазона разрядов той комбинации x1, x2 и x3, на которой достигается этот максимум (Рис.5).

Рис.5. Формулы выбора лучшего решения.
Для облегчения визуального поиска лучшего решения столбец с суммарной эффективностью рационально условно отформатировать на равенство максимальному значению суммарной эффективности. Фрагмент листа с отображением окончательного решения представлен на Рис.6.
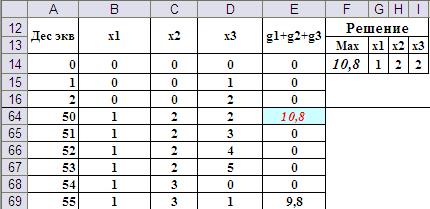
Рис.6. Окончательные результаты решения методом перебора.
«Поиск решения». Средство «Поиск решения» позволяет накладывать ограничения целочисленности переменных. Поэтому данная задача может быть решена этим средством.
На Рис.7 представлена возможная организация рабочего листа, а Рис.8 – настройка опций средства «Поиск решения».
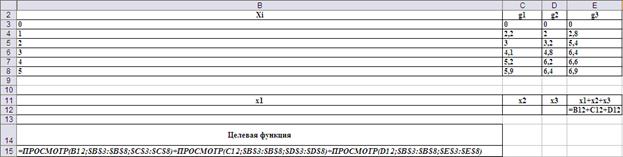
Рис.7. Организация рабочего листа при использовании средства «Поиск решения»
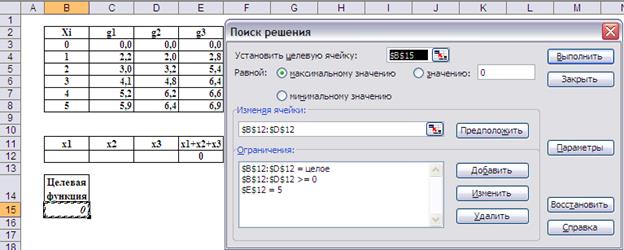
Рис.8. Настройка опций средства «Поиск решения»
Результаты решения (Рис.9) совпадают с результатами, полученными методом перебора.
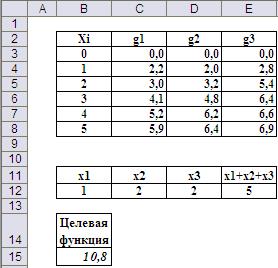
Рис.9. Окончательные результаты решения с помощью средства «Поиск решения»
Метод динамического программирования. Рассмотренные выше методы решения рационально применять при малых размерностях задачи. В случае большого количество предприятий и большой суммы инвестиций применяют метод динамического программирования.
В соответствии с идеей метода задача решается в два этапа.
1 этап. Условная оптимизация (k=3, 2, 1).
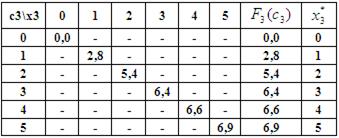
1-ый шаг: k=3. Он выполняется в предположении, что все средства в количестве x3=5 млн. руб. отданы третьему предприятию. В этом случае максимальный доход, как видно из таблицы исходных данных и таблицы для функции Беллмана 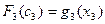 составит
составит 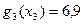 млн. руб.
млн. руб.
2-ой шаг: k=2. Определяем оптимальную стратегию при распределении денежных средств между вторым и третьим предприятиями. При этом рекуррентное соотношение Беллмана имеет вид:
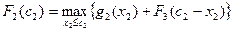
На основе последнего соотношения строится таблица для функции Беллмана 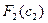
3-ой шаг: k=1. Определяем оптимальную стратегию при распределении денежных средств между первым и двумя другими предприятиями, используя формулу для расчёта суммарного дохода:
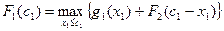 ,
,
на основе которого составлена таблица для функции Беллмана 
2 этап. Безусловная оптимизация (k=1, 2, 3).
Определяем траекторию оптимальной стратегии.
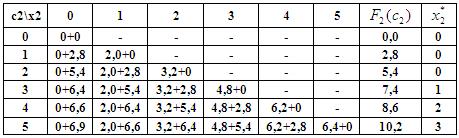
1-ый шаг: k=1. По данным таблицы для функции Беллмана оптимальный план при распределении 5 млн. руб. между тремя предприятиями составляет: 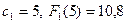 . При этом первому предприятию нужно выделить
. При этом первому предприятию нужно выделить 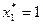 млн. руб.
млн. руб.
2-ой шаг: k=2. Определяем величину оставшихся денежных средств, приходящуюся на долю второго и третьего предприятий:
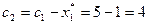 млн. руб.
млн. руб.
По данным таблицы для функции Беллмана находим, что оптимальный вариант распределения денежных средств размером 4 млн. руб. между вторым и третьим предприятиями составляет: 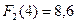 при выделении второму предприятию
при выделении второму предприятию 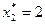 млн. руб.
млн. руб.
3-ий шаг: k=3. Определяем величину оставшихся денежных средств, приходящуюся на долю третьего предприятия:
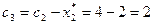 млн. руб.
млн. руб.
По данным таблицы для функции Беллмана 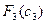 находим:
находим:
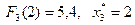 млн. руб.
млн. руб.
Траектория шагов второго этапа наглядно представлена на Рис.10.
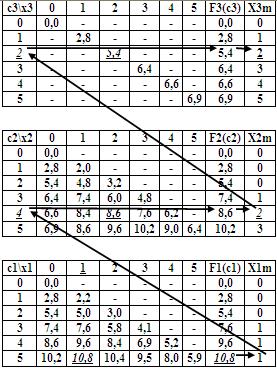
Рис.10. Траектория шагов второго этапа оптимизации методом динамического программирования
Таким образом, оптимальный план инвестирования предприятий: 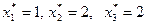 , который обеспечивает максимальный доход, равный
, который обеспечивает максимальный доход, равный
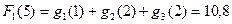 млн. руб.
млн. руб.
Итак, задача оптимального распределения инвестиций между тремя предприятиями решена тремя способами. Все они дали одинаковые результаты. Какому из них отдавать предпочтение при решении подобных задач? Рекомендации следующие. При малых размерностях проще решать методом перебора или с помощью средства «Поиск решения». Эти методы просты для понимания и для реализации. Однако при больших размерностях рационально использовать алгоритм динамического программирования. Он устойчив в решении и наиболее быстродействующий. Освоение метода требует определённых умственных усилий. Выше рассмотрено решение данным методом «вручную». Для решения подобных задач с другими исходными данными рационально автоматизировать процесс составления таблиц функций Беллмана.
На Рис.11 показан возможный вариант организации таблиц на листе приложения MS Excel.
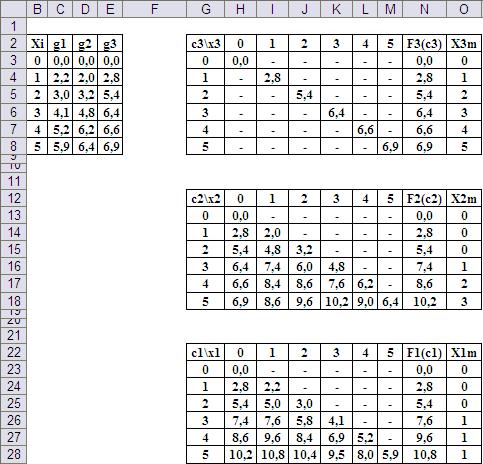
Рис.11. Организация данных на рабочем листе.
На Рис.12 показан фрагмент рабочего листа в режиме отображения формул. Ячейки H3, H13 и H23 соответствуют верхним левым углам таблиц функций Беллмана , , , соответственно. Адресация ячеек в формулах обеспечивает автоматическое заполнение всех таблиц при распространении формул по всему полю таблиц.
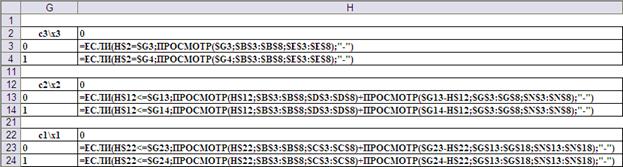
Рис.12. Ввод формул в ячейки рабочего листа для заполнения основных полей таблиц функций Беллмана
Вычисление максимальных значений функций и нахождение соответствующих значений аргументов осуществляется с помощью функций МАКС() и ПОИСКПОЗ() (Рис.13).
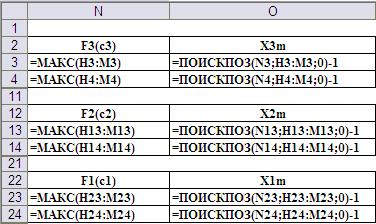
Рис.13. Ввод формул в ячейки рабочего листа нахождения максимальных значений функций и нахождения соответствующих аргументов.
§
§
Математический аппарат динамического программирования, основанный на методологии пошаговой оптимизации, может быть использован при нахождении кратчайших расстояний, например на географической карте, представленной в виде графа. Решение задачи по определению кратчайших расстояний между пунктами отправления и пунктами получения продукции по существующей транспортной сети является исходным этапом при решении таких экономических задач, как оптимальное прикрепление потребителей к поставщикам, повышение производительности транспорта за счёт сокращения непроизводительного пробега и др.
Задача нахождения кратчайшего маршрута методом динамического программирования решается следующим образом. Вводится функция fi, определяющая минимальную длину из начальной вершины в вершину i. Через Sij обозначают длину пути между вершинами i и j, а fj – наименьшую длину пути между вершиной j и начальной вершиной.
Выбирая в качестве i такую вершину, которая минимизирует сумму 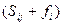 , получают функциональное уравнение Беллмана
, получают функциональное уравнение Беллмана
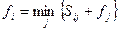
Сложность решения данного уравнения существенно зависит от вида графа, описывающего транспортную сеть. Если граф направленный, задача решается достаточно просто.
На Рис.1 представлен ориентированный граф.
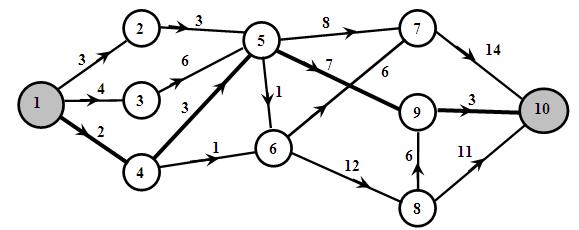
Рис.1. Взвешенный ориентированный граф.
Для упрощения и систематизации составления функций Беллмана рационально пронумеровать вершина так, чтобы дуга выходила из вершины с меньшим номером. Граф на Рис.1 этому требованию удовлетворяет. В этом случае последовательно находят функции fi для каждой вершины ориентированного графа.
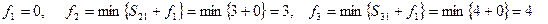

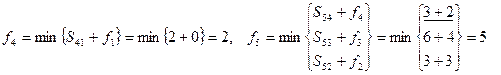
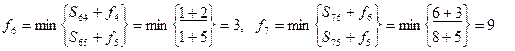
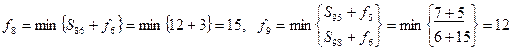
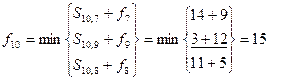
Длина кратчайшего пути составляет 15 условных единиц. Для выбора оптимальной траектории осуществляют просмотр функций fi в обратном порядке. В данном случае
Минимальная выбранная сумма 3 12=15 соответствует вершине с номером 9.
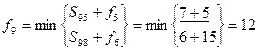
При вычислении f9 была выбрана вершина 5. Продолжая таким же образом, получим кратчайший путь от вершины 1 к вершине 10 (1, 4, 5, 9, 10)
На Рис.1 дуги этого пути изображены жирными линиями.
Для ненаправленных графов решение функционального уравнения Беллмана существенно усложняется. На Рис.2 представлен взвешенный неориентированный граф. Топологически граф соответствует графу на Рис.1. Однако ориентация ветвей отсутствует.
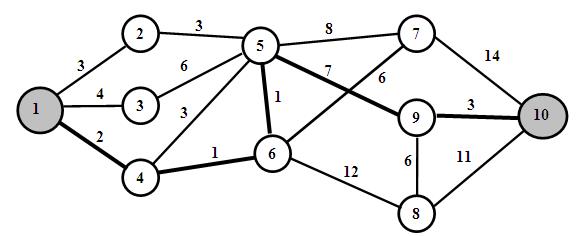
Рис.2. Взвешенный неориентированный граф.
Система уравнений Беллмана для графа на Рис.2 выглядит следующим образом:
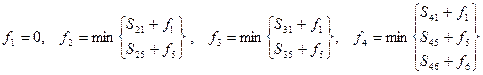
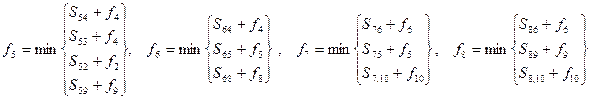
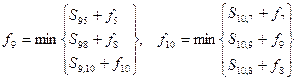
В данном случае не представляется возможным последовательно вычислить fi, т.к. неизвестная функция входит в обе части равенств, образующих систему. В этой ситуации прибегают к классическому методу последовательных приближений (итераций), используя рекуррентную формулу
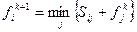
Расчёты по данному методу, проведённые в приложении M Excel, сведены в таблицу
| Ите-ра- ция | Узел | Приз-нак завер-шения итера-ций | ||||||||||||||||||||
| f0 | ||||||||||||||||||||||
| f | ||||||||||||||||||||||
| f | ||||||||||||||||||||||
| f | ||||||||||||||||||||||
| f | ||||||||||||||||||||||
| f | ||||||||||||||||||||||
| f | ||||||||||||||||||||||
| f | V | |||||||||||||||||||||
Основу таблицы составляет фрагмент

Как следует из таблицы, итерационный процесс завершился за шесть шагов (результаты на седьмой итерации совпали с результами на шестом). Длина кратчайшего пути равна 14. Траектория пути определяется просмотром функций fi в обратном порядке. По фрагменту таблицы на шестой итерации видно, что минимальное значение 14 соответствует вершине 9. Далее, f9=11. Значение 11 соответствует вершине 5. Если таким же образом продвигаться в обратном порядке, получим кратчайший путь от вершины 1 к вершине 10:
(1, 4, 6, 5, 9, 10)
Для автоматизации расчётов рационально топологию графа задать матрицей смежностей
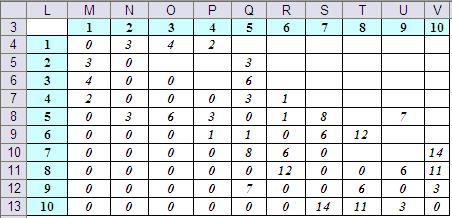
Формулы, введённые в ячейки базового фрагмента таблицы, представлены на Рис.3.
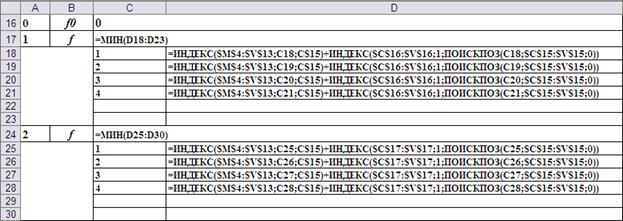
Рис.3. Ввод формул в базовый фрагмент таблицы.
В ячейку D18 введена формула:
=ИНДЕКС($M$4:$V$13;C18;C$15) ИНДЕКС($C$16:$V$16;1;ПОИСКПОЗ(C18;$C$15:$V$15;0))
Она реализует вычисление суммы 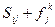 . Первая часть формулы ИНДЕКС($M$4:$V$13;C18;C$15) извлекает из матрицы смежностей длину дуги между узлами i и j. Вторая часть ИНДЕКС($C$16:$V$16;1;ПОИСКПОЗ(C18;$C$15:$V$15;0)) выбирает соответствующее значение
. Первая часть формулы ИНДЕКС($M$4:$V$13;C18;C$15) извлекает из матрицы смежностей длину дуги между узлами i и j. Вторая часть ИНДЕКС($C$16:$V$16;1;ПОИСКПОЗ(C18;$C$15:$V$15;0)) выбирает соответствующее значение 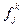 из предыдущей итерации. За счёт надлежащей адресации ячеек в формуле она (формула) может распространена в соответствующие ячейки всей таблицы.
из предыдущей итерации. За счёт надлежащей адресации ячеек в формуле она (формула) может распространена в соответствующие ячейки всей таблицы.
Итерационный метод может быть использован и для нахождения кратчайшего пути в ориентированном графе. Для этого достаточно в матрице смежностей в качестве длин дуг в обратном направлении указать взять большие значения, которые не будут выбраны в соответствии с сутью метода. На Рис.4 показана матрица смежностей, описывающая направленный граф, представленный на Рис.1, а на Рис.5 – результат решения на 4-ой итерации. Ответ, естественно, совпадает с результатом, полученным ручным образом.
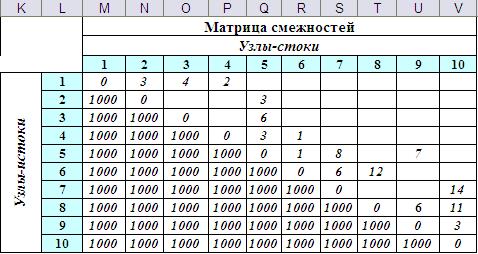
Рис.4. Матрица смежностей ориентированного взвешенного графа
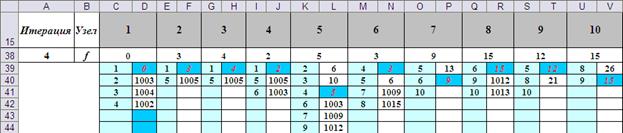
Рис.5. Результат поиска кратчайшего пути для ориентированного графа.
§
Алгоритм Дейкстры предназначен для нахождения кратчайшего пути между вершинами в неориентированном графе.
Идея алгоритма следующая: сначала выбирается путь до начальной вершины равным нулю, эта вершина заносится во множество уже выбранных, расстояние от которых до оставшихся невыбранных определено. На каждом этапе находится следующая невыбранная вершина, расстояние до которой наименьшее, и соединённая с какой-нибудь вершиной из множества выбранных (это расстояние будет равно расстоянию до уже выбранной вершины плюс длина ребра)[2, 3].
В качестве примера рассмотрим задачу нахождения кратчайшего пути от вершины A до вершины D для графа на Рис.6.
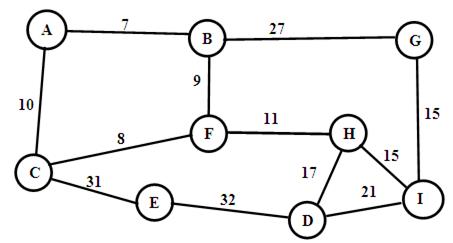
Рис.6. Взвешенный неориентированный граф.
На Рис.7 представлен фрагмент рабочего листа приложения MS Excel, на котором реализован алгоритм Дейкстры для сформулированной задачи.
Шаг 1-ый. Выбираем вершину A. Выбранная вершина напрямую связана с вершинами B и C. Расстояние до B равно 7, а до C – 10. Поэтому дополняем множество выбранных вершин вершиной B.
Шаг 2-ой. От выбранного множества A и B кратчайшее прямое расстояние до вершины F. Поэтому дополняем множество выбранных вершин вершиной F.
Шаг 3-ий. От выбранного множества A, B и F кратчайшее прямое расстояние до вершины E. Дополняем множество выбранных вершин вершиной E.
Шаг 4-ый. От выбранного множества A, B,F и E кратчайшее прямое расстояние до вершины H. Дополняем множество выбранных вершин вершиной H.
Шаг 5-ый. От выбранного множества A, B, F, E и H кратчайшее прямое расстояние до вершины G. Дополняем множество выбранных вершин вершиной G.
Шаг 6-ой. От выбранного множества A, B, F, E, H и G кратчайшее прямое расстояние до вершины I. Дополняем множество выбранных вершин вершиной I.
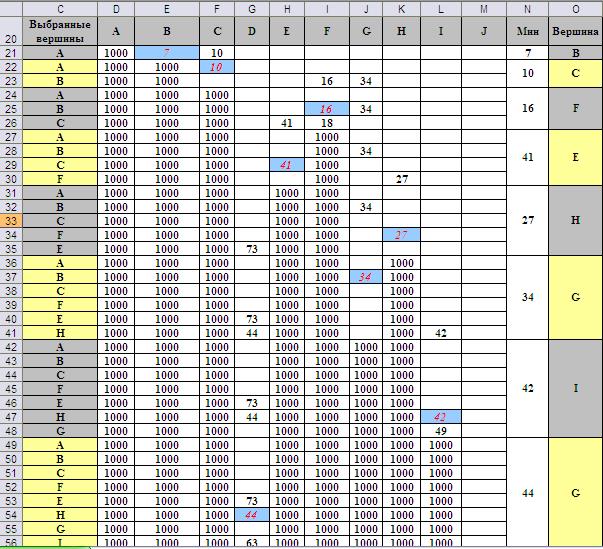
Рис.7. Поиск кратчайшего пути с помощью алгоритма Дейкстры.
Шаг 7-ой. От выбранного множества A, B, F, E, H, G и I кратчайшее прямое расстояние до вершины целевой вершины B. Процесс нахождения минимального расстояния завершён.
Выбор траектории осуществляется просмотром сформированной таблицы в обратном порядке и представлен наглядно на Рис.8.
Итак, минимальная длина пути от вершины A до вершины D составляет 44 условных единиц. Траектория кратчайшего пути (A, B, F,H, D).
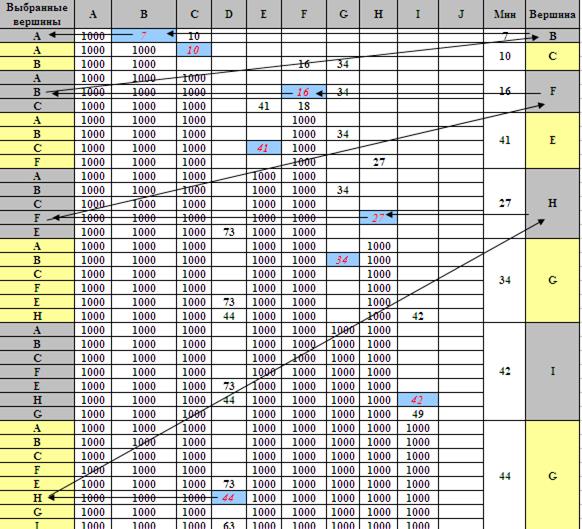
Рис.8. Выбор оптимальной траектории.
§
§
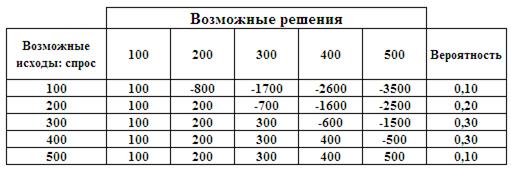
В лабораторной работе рассматриваются стратегии принятия оптимальных решений в условиях риска для торговых предприятий. Одной из важных задач, решаемых предприятиями торговли, является определение оптимального объёма заказа на товары у поставщика. Недозаказ может привести к неудовлетворённому спросу и, следовательно, к недополучению прибыли. А заказ излишнего количества товара может привести к необходимости реализации перезаказанного товара по ценам ниже закупочных цен, что вызовет прямые убытки. Решающим фактором при определении объёма заказа является спрос, который подвержен влиянию множества случайных факторов: тенденциям моды, погоды и др. Задача принятия оптимального решения проводится на основе анализа матрицы полезности (или прибыли) 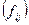 [1, 3, 5]
[1, 3, 5]
Строки матрицы соответствуют состояниям среды (спросу), а столбцы принимаемым решениям (объёмам заказа). Элемент матрицы 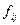 равен величине прибыли, если спрос находится в состоянии
равен величине прибыли, если спрос находится в состоянии 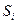 , а менеджерами принято решениезаказать
, а менеджерами принято решениезаказать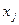 единиц товара. При известных вероятностных характеристиках среды матрица может быть дополнена столбцом со значениями вероятностей пребывания среды в каждом состоянии.
единиц товара. При известных вероятностных характеристиках среды матрица может быть дополнена столбцом со значениями вероятностей пребывания среды в каждом состоянии.
Конкретизируем задачу для следующей ситуации. Менеджер небольшой кондитерской «Сластёна» решает вопрос, сколько пирожных следует иметь в запасе, чтобы удовлетворить спрос покупателей. Каждое пирожное обходится у поставщика в 10 руб., а кондитерская продаёт его по 15 руб. Продать невостребованные пирожные на следующий день невозможно, поэтому остаток распродаётся в конце дня по 5 руб. за штуку. Перечисленные цены сведены в таблицу
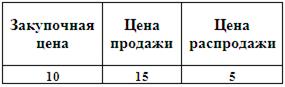
За сорок пять предыдущих дней работы была набрана статистика на спрос.
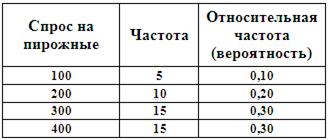
Сформируем матрицу полезности для данного случая. Количество проданных пирожных определяется выражением 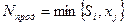 . В самом деле, если
. В самом деле, если 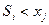 , то реализуется пирожных, т.к. нет спроса. Если же
, то реализуется пирожных, т.к. нет спроса. Если же 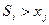 , то реализуется пирожных, т.к. предложение недостаточное. Таким образом, распродаже подлежит
, то реализуется пирожных, т.к. предложение недостаточное. Таким образом, распродаже подлежит 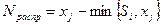 пирожных. Это соотношение предполагает и нулевое значение, если
пирожных. Это соотношение предполагает и нулевое значение, если 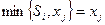 . Затраты на закупку составят
. Затраты на закупку составят 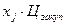 . Следовательно, элемент матрицы полезности определяется соотношением
. Следовательно, элемент матрицы полезности определяется соотношением
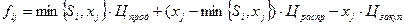
где:  — цена продажи,
— цена продажи,  — цена распродажи.
— цена распродажи.
Заполнение матрицы полезности по выведенной формуле приведет к результату.
На практике применяют два правила принятия оптимального решения:
· правило максимальной вероятности;
· правило максимальной средней прибыли.
Правило максимальной вероятности – максимизация наиболее вероятных доходов. При этом в матрице доходов выбирают состояния спроса, имеющие наибольшие вероятности, и в пределах этих состояний выбирают решение, которое даёт наибольший доход.
На Рис.1 показана подготовка листа приложения MS Excel для автоматизации данного правила. Адресация в формуле ячейки позволяет распространить её во все ячейки матрицы полезности. Поэтому ряд столбцов на Рис. 1 скрыт.
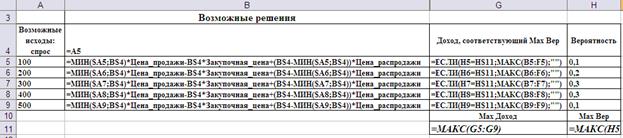
Рис.1. Ввод формул для реализации правила максимальной вероятности.
Оптимальное решение по правилу максимальной вероятности для приведённых исходных данных соответствует объёму закупки 400 (Рис.2).
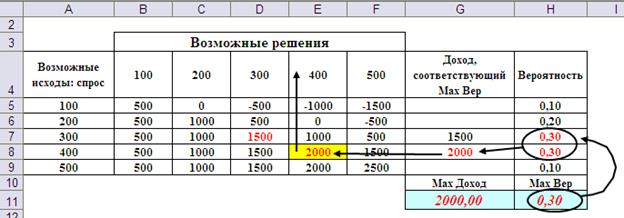
Рис.2. Оптимальное решение для правила максимальной вероятности.
Правило средней прибыли. Этот способ использования вероятностных характеристик при принятии решения является наиболее распространённым. Решающее правило для определения оптимальной стратегии 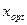 формально записывается так
формально записывается так
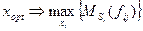 ,
,
где: 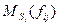 — математическое ожидание прибыли при усреднении по спросу.
— математическое ожидание прибыли при усреднении по спросу.
Т.е., сначала получают средние значения прибылей в пределах каждого столбца, а затем из столбцов (объёмов закупок) выбирается тот, для которого среднее значение максимально.
На Рис.3 и Рис.4, соответственно, показаны подготовка листа для автоматизации принятия решения и результат выбора по данному правилу. Оптимальный объём закупки в данном случае равен 300, что отличается от результата, полученного по правилу максимальной вероятности.
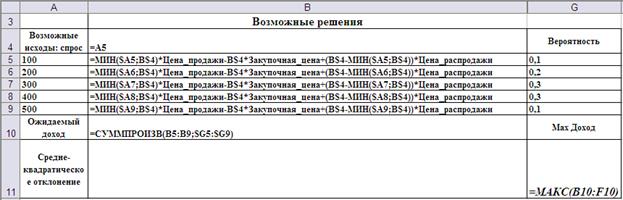
Рис.3. Ввод формул для реализации правила максимальной ожидаемой прибыли.
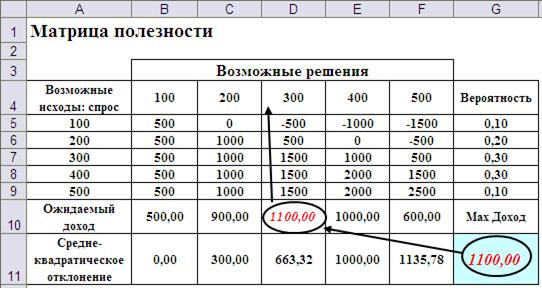
Рис.4. Оптимальное решение для правила максимальной ожидаемой прибыли.
В том случае если максимальных средних значений по столбцам окажется несколько, следует отдать предпочтение тому, для которого среднеквадратическое отклонение окажется меньшим.
§
§
В задачах оптимизации, когда необходимо учитывать некоторый случайный фактор (элемент или явление), который невозможно описать аналитически, используют метод моделирования, называемый методом статистических испытаний или методом Монте-Карло [4,5]. С помощью этого метода может быть решена любая вероятностная задача. Однако использовать его целесообразно в том случае, если решить задачу этим методом проще, чем любым другим.
Суть метода состоит в том, что вместо описания случайных явлений аналитическими зависимостями проводится розыгрыш случайного явления с помощью некоторой процедуры, которая дает случайный результат. С помощью розыгрыша получают одну реализацию случайного явления. Осуществляя многократно такой розыгрыш, накапливают статистический материал (множество реализаций случайной величины), который можно обрабатывать статистическими методами. Рассмотрим этот метод на примерах.
Пример 1. Трость длиной L разламывается на три части. Расстояния от начала трости до двух точек перелома – непрерывные случайные величины с равномерным законом распределения. Найти вероятность того, что из получившихся частей можно собрать треугольник.
В теории вероятностей эта задачу называют задачей о «сломанной трости». Эту задачу можно решить методами теории вероятности.
Обозначим через x и y расстояния от левого конца трости первой и второй точек перелома (Рис.1).
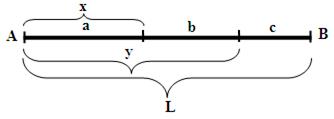
Рис.1. Условные обозначения для задачи о «сломанной трости»
Тогда длины сторон возможного треугольника выражаются через L, x и y следующим образом
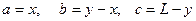
Длины сторон треугольника должны удовлетворять условию: сумма длин двух любых сторон больше (или в вырожденном случае равна) длине третьей стороны. Таким образом, имеем систему неравенств
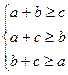
После подстановки длин сторон треугольника через L, x и y получим
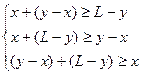
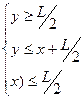
Решение полученной системы неравенств можно наглядно иллюстрировать на двухкоординатной плоскости. (Рис.2). Т.к. величины x и y имеют равномерное распределение на отрезке [0; L], то множеству точек со всевозможными координатами (x;y) соответствует квадрат OPRS со стороной L. Тогда точки, координаты которых удовлетворяют составленной системе неравенств с учётом условия 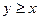 , принадлежат области, ограниченной треугольником ABC. Если провести аналогичные рассуждения для случая
, принадлежат области, ограниченной треугольником ABC. Если провести аналогичные рассуждения для случая 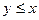 , то получим треугольник CDE.
, то получим треугольник CDE.
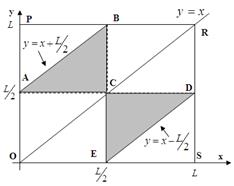
Рис. 2. Графическая иллюстрация решения задачи Примера 1.
Искомая вероятность равна доле суммарной площади треугольников от площади квадрата OPRS
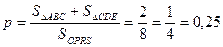
Решим эту задачу методом статистических испытаний. Для этого в приложении MS Excel создадим таблицу, как показано на Рис. 3.
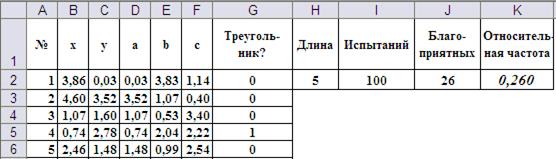
Рис.3. Структура таблицы для решения задачи Примера 1 методом статистических испытаний.
На Рис.4a-b показан ввод формул в ячейки листа для решения задачи Примера 1 методом статистических испытаний.

Рис.4a. Ввод формул для реализации случайного перелома трости и проверки возможности формирования треугольника.
 м
м
Рис.4b. Ввод формул для обработки серии испытаний.
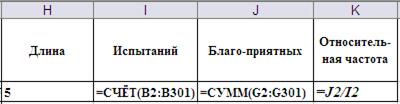
Моделирование координат точек перелома x и y осуществляется по формулам «=Длина*СЛЧИС()»(см. формулы в ячейках B2 и C2). Встроенная функция СЛЧИС() генерирует случайную величину, равномерно распределённую на отрезке [0;1]. Выбор в качестве стороны a минимального значения 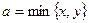 и расчёт сторон b и c по формулам
и расчёт сторон b и c по формулам
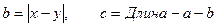
позволяет учесть оба случая, когда и (см. формулы в ячейках D2, E2 и F2).
С помощью логических суперпозиции логических функций ЕСЛИ() и И() в ячейке G2 обеспечивается поверка возможности собрать треугольник из фрагментов трости. При этом возможность кодируется единицей, а невозможность нулём. Такая кодировка позволяет просто подсчитать число благоприятных исходов с помощью функции СУММ() (ячейка J2)
Формулы в ячейках H2, I2, J2 и K2 обеспечивают подсчёт общего числа испытаний, числа благоприятных исходов и их долю в общем числе испытаний.
При каждом нажатии функциональной клавиши F9 Excel пересчитывает функции СЛЧИС() и, таким образом, моделирует новую серию испытаний. В каждой серии получается новое значение вероятности (на Рис. 3 она равна 0,26). В качестве оценки вероятности берут среднее арифметическое от нескольких серий. Усреднение десяти выборочных значений представлено в таблице:

Полученное среднее значение 0,247 близко к значению, рассчитанному теоретически 0,250. На практике такой точности вполне достаточно.
Таким образом, алгоритм метода статистических испытаний сводится к следующему.
· Определить, что собой будет представлять испытание или розыгрыш.
· Определить, какое испытание является успешным, а какое– нет.
· Провести большое количество испытаний.
· Обработать полученные результаты статистическими методами и рассчитать статистические оценки искомых величин.
При проведении статистических испытаний необходимо воспроизводить случайные величины с нужным законом распределения. Приложение MS Excel имеет для этого достаточное число средств. Простейшими является функция СЛЧИС() и СЛУЧМЕЖДУ(a,b). Первая функция генерирует случайное число с равномерным законом распределения на полуинтервале [0;1) (Рис. 5), вторая — случайное число с равномерным законом распределения на интервале (a;b) (Рис. 6).
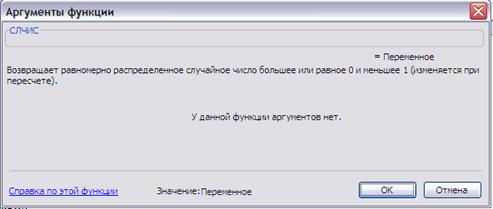
Рис.5. Конструктор функции СЛЧИС().
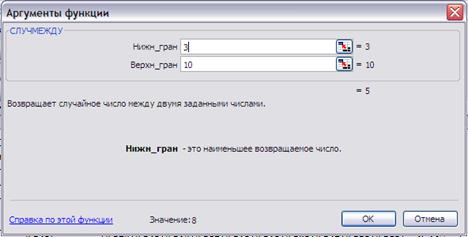
Рис.6. Конструктор функции СЛУЧМЕЖДУ(a;b).
Кроме того, MS Excel располагает надстройкой «Пакет анализа», которая содержит генератор случайных величин с различными функциями распределения (Рис.7).
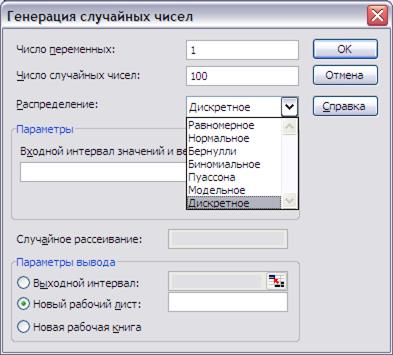
Рис.7. Диалоговое окно генератора случайных чисел.
Перечисленные средства предоставляют практически неограниченные возможности по моделированию случайных величин.
Моделирование события. Пусть необходимо смоделировать появление некоторого события А, вероятность наступления которого равняется Р(А)=Р. Это можно смоделировать суперпозицией функций:
=ЕСЛИ(СЛЧИС()<=P; “произошло событие А”; “событие А не произошло”)
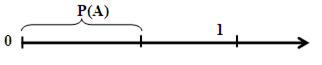
Рис. 8. Вероятность наступления события А
Моделирование группы несовместимых событий. Пусть есть группа несовместимых событий А1, А2,..,.Аk. Известны вероятности наступления событий Р(А1), Р(А2),…, Р(Аk). Тогда из-за несовместимости испытаний 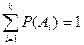 . На отрезке [0, 1] отложим эти вероятности (Рис. 9).
. На отрезке [0, 1] отложим эти вероятности (Рис. 9).
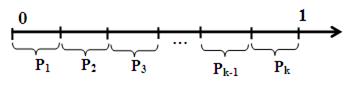
Рис. 9. Вероятности наступления группы несовместимых событий
Если число, сгенерированное функцией СЛЧИС() попало в i-ый интервал, то произошло событие Аi.
Моделирование условного события. Моделирование условного события B, которое происходит при условии, что наступило событие A с вероятностью Р(B/A), показано на рис. 10. Сначала моделируем событие A. Если событие A происходит, то моделируем наступление события B, если имеем  , то не моделируем наступление события B.
, то не моделируем наступление события B.
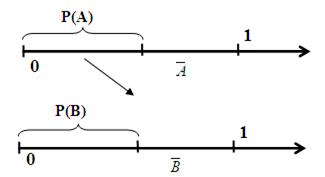
Рис. 10. Моделирование условного события B
Рассмотрим пример на моделирование условных событий.
Пример 2. В сборочный цех поступили детали с трех предприятий. На первом предприятии изготовлено 51% деталей от их общего количества, на втором предприятии 24% и на третьем 25%. При этом на первом предприятии было изготовлено 90% деталей первого сорта, на втором 80% и на третьем 70%. a) Какова вероятность того, что взятая наугад деталь окажется первого сорта? b) Какова условная вероятность того, что если взятая наугад деталь оказалась бракованной, она была изготовлена на первом предприятии?
Решение:Сначала решим задачу по формулам, используя соответствующие формулы теории вероятностей.
a) Пусть A — cобытие, состоящее в том, что взятая деталь окажется первого сорта, а H1, H2 и H3 — гипотезы, что она изготовлена соответственно на 1, 2 и 3 предприятии. Вероятности этих гипотез соответственно равны:
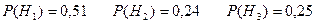
Далее, из условия задачи следует, что:
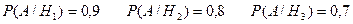
Используя формулу полной вероятности, получим искомую вероятность
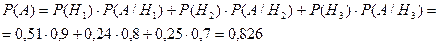
b) Изделие выбирается наудачу из всей произведённой продукции и оказывается бракованным. Рассмотрим три гипотезы: Hi – деталь изготовлена на i-ом предприятии i=1,2,3. Вероятности этих событий даны:
Пусть изделие оказалось бракованным. Условные вероятности этого по отдельным предприятиям:
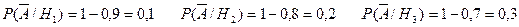
Тогда искомая условная вероятность считается как доля бракованных изделий первого предприятия относительно общего числа брака:
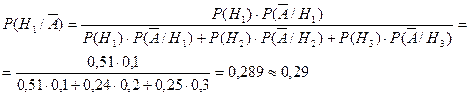
Итак, задача решена. Её решение потребовало знаний соответствующих разделов теории вероятностей, в частности, формул расчёта полной и условной вероятностей. При решении задачи методом статистических испытаний этих соотношений можно не знать.
Исходные данные рационально организовать, как показано на Рис.11. Таблицы вероятностей дополнены тремя столбцами «Просмотр», «Результат» и «Номер события». Это необходимо для реализации моделирования группы несовместимых событий и моделирования условных событий. На Рис.12 данный фрагмент листа представлен в режиме показа формул. В столбце «Просмотр» сформирована сумма вероятностей нарастающим итогом. Тем самым формируются границы событий согласно идее, представленной на Рис.9. Моделирование наступления одного из несовместимых событий реализуется по следующей схеме:
· моделирование с помощью функции СЛЧИС() случайной величины с равномерным законом распределения на полуинтервале [0;1);
· поиск полученного значения с помощью функции ПРОСМОТР() в столбце «Просмотр» и извлечение из таблицы названия события из столбца «Результат» или его условного номера из столбца «Номер события».
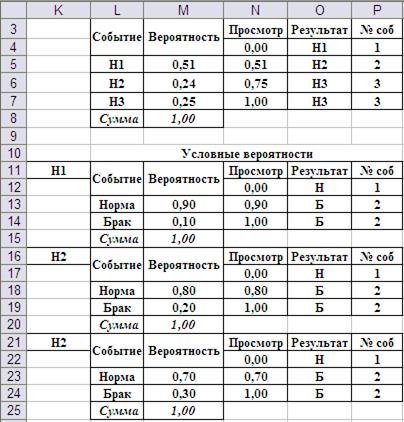
Рис. 11. Организация таблиц исходных данных
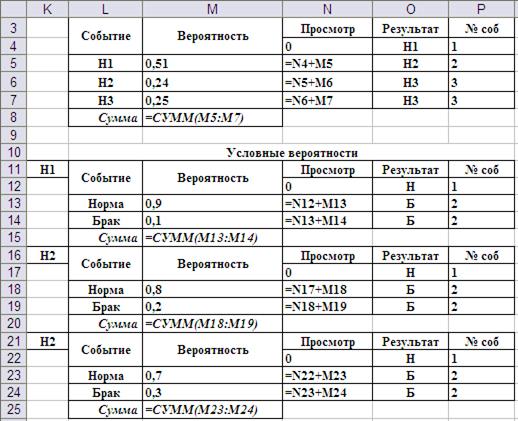
Рис. 12. Ввод формул в исходные таблицы данных
На Рис. 13-14a)-c) показаны, соответственно, общий вид таблицы статистического моделирования и введённые формулы. Выбор значений условных вероятностей брака и деталей первого сорта из таблиц осуществляется с помощью суперпозиции функций ПРОСМОТР() и СМЕЩ(). Первая осуществляет непосредственно выбор из таблицы, а обращение к нужной таблице в зависимости от номера смоделированного предприятия происходит с помощью функции СМЕЩ(). Для этого таблицы условных вероятностей должны располагаться с одинаковым шагом (в данном случае с шагом 5).
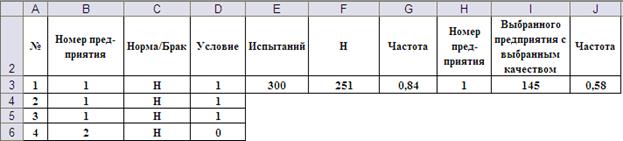
Рис. 13. Общий вид таблицы статистических испытаний

a)
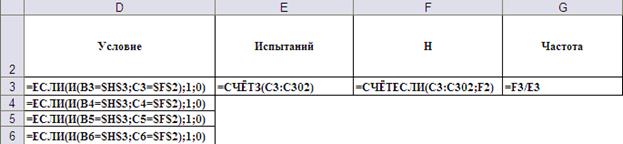
b)

c)
Рис. 14. Ввод формул в таблицу статистических испытаний
Усреднение результатов проведённого моделирования в соответствии с пунктами задания Примера 2 приведено в таблицах:


Отмечаем близость полученных результатов моделирования к теоретическим расчётам.
Метод статистических испытаний может успешно применяться для решения многих других задач, имеющих детерминистский характер. В частности, этим методом наглядно, правда приблизительно, решаются задачи линейного и нелинейного программирования, задачи построения множеств точек, координаты которых удовлетворяют системе неравенств.
Алгоритм решения сводится к следующему:
· моделирование случайного множества точек в n-мерном пространстве;
· выбор из сформированного множества подмножества точек, координаты которых удовлетворяют системе ограничений;
· выбор из полученного подмножества за счёт сортировки в нужном порядке точки, с максимальным или минимальным значением целевой функции;
· построение для двухмерного случая области ограничения на переменные.
На Рис. 15 показана полученная по этому алгоритму область ограничения на переменные X и Y при решении следующей нелинейной оптимизационной задачи:
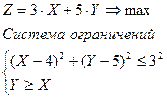
Оптимальное решение достигается в точке с координатами: X=5,53; Y=7,54, в которой целевая функция принимает значение Zmax=54,28. Точное решение, полученное с помощью средства «Поиск решения»: X=5,54; Y=7,57, Zmax=54,49. Иллюстрация точного решения показана на Рис.16. Как видим, погрешность удовлетворяет практическим требованиям.
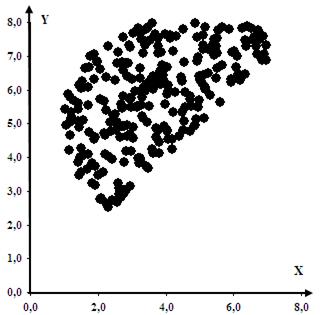
Рис. 15. Область ограничений, построенная методом статистических испытаний.
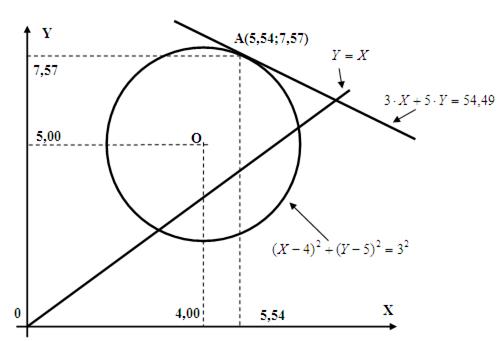
Рис. 16. Графическая иллюстрация точного решения задачи нелинейной оптимизации.
§
§
Пример. Фирма «Гигант» разрабатывает инвестиционный проект производства банковских сейфов нового поколения. Инвестиции в данный проект намечено производить в три этапа.
1-ый этап. В начальный момент времени необходимо затратить $500 тыс. на проведение маркетингового исследования рынка.
2-ой этап. Если в результате проведённого исследования обнаружено, что потенциал рынка достаточно высок, то в следующий момент времени фирма «Гигант» инвестирует дополнительно $1000 тыс. на разработку и создание опытных образцов сейфов, подлежащих экспертизе в Специальном центре по безопасности банков, специалисты которого решают вопрос о размещении заказа в данной фирме.
3-ий этап. Если экспертная комиссия вынесла положительное решение о представленных сейфах, то фирма начинает строительство нового предприятия и организацию серийного производства сейфов, для чего ей потребуется ещё $10000 тыс. Реализация данной стадии, по оценкам аналитиков и менеджеров проекта, обеспечит возможность генерирования проектом притоков наличности в течение четырёх лет. Величина притоков зависит от того. Насколько хорошо сейф принят на рынке.
Для анализа и оценки риска рассматриваемого многостадийного процесса целесообразно использовать метод дерева решений (Рис.1)..
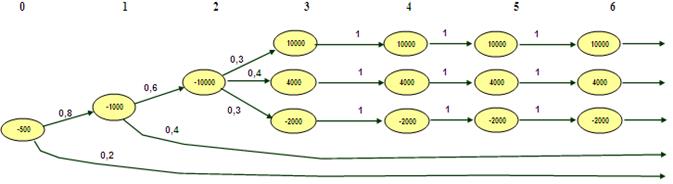
Рис.1. Дерево решения для проекта производства сейфов.
Исходим из предположения, что очередное решение об инвестировании принимается фирмой в конце года. Каждое «разветвление» означает точку принятия решения, либо очередной этап. Число, записанное внутри вершины графа, означает размер инвестиций или размер притока наличностей. Очевидно, что инвестиции записываются отрицательными числами, а притоки наличностей – положительными. Числа на дугах дерева означают вероятности переходов в различные состояния. Так, если фирма «Гигант» решает реализовывать проект в момент времени t=0, то она должна потратить $500 тыс. на проведение маркетингового исследования. По оценкам менеджеров компании, вероятность благоприятного результата равна 0,8, а вероятность получения неблагоприятного результата – 0,2. На дереве решений это отображается самой левой вершиной и двумя дугами, выходящих из неё (момент времени t=0).
Если по результатам маркетингового исследования руководство фирмы приходит к оптимистическому заключению о потенциале рынка, то в момент времени t=1 необходимо потратить ещё $1000 тыс. на изготовление экспериментального образца сейфа. Менеджеры фирмы оценивают вероятность положительного исхода в 0,6, а вероятность отрицательного исхода – 0,4 (вершина с размером инвестиций -1000 и дуги 0,6 и 0,4 в момент времени t=1 на дереве решений).
В случае, если экспертный совет находит данную модель сейфа привлекательной, фирма в момент времени t=2 должна израсходовать ещё $10000 тыс. на строительство нового предприятия и организации серийного производства сейфов. Если фирма «Гигант» приступает к производству сейфов, то операционные потоки наличности в течение четырёхлетнего срока жизни проекта зависят от того, насколько хорошо продукт будет «принят» рынком. По оценкам маркетологов, вероятность того, что рынок положительно воспримет продукт, составляет 0,3, и в этом случае чистые притоки наличности должны составлять около $10000 тыс. ежегодно. Вероятности того, что притоки наличности будут составлять около $4000 тыс. и -$2000 тыс. в год, равны 0,4 и 0,3 соответственно. Эти ожидаемые потоки наличности на дереве решений показаны с третьего года по шестой.
Вероятность реализации пути от начальной вершины до выхода равна произведению вероятностей дуг на этом пути.
В предположении, что средняя учётная банковская ставка составляет 11,5%, рассчитаем чистый дисконтированный доход ( 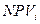 ) по каждому из вариантов, представленных деревом решений
) по каждому из вариантов, представленных деревом решений
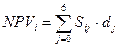 ,
,
где: 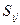 — величина инвестиции (притока наличности) при i-ом варианте решения на j-ом году проекта;
— величина инвестиции (притока наличности) при i-ом варианте решения на j-ом году проекта;
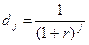 — дисконтирующий множитель для j-ого года;
— дисконтирующий множитель для j-ого года;
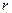 — учётная банковская ставка.
— учётная банковская ставка.
Затем, умножая значения чистого дисконтированного дохода на соответствующее значение вероятности 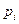 , получаем ожидаемый чистый дисконтированный доход инвестиционного проекта.
, получаем ожидаемый чистый дисконтированный доход инвестиционного проекта.
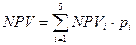 ,
,
Расчёты по изложенной методике реализованы в приложении MS Excel (Рис.2). Ввод формул в ячейки рабочего листа не показан в силу их простоты.
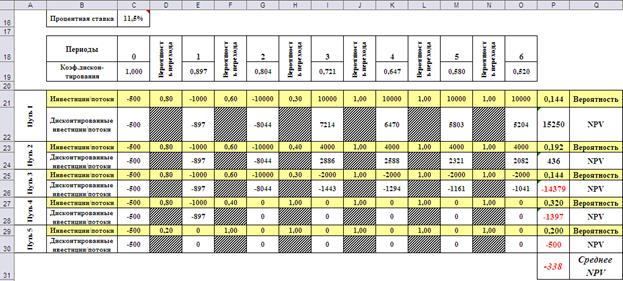
Рис.2. Результаты расчётов для проекта производства сейфов.
Поскольку значение ожидаемого чистого дисконтированного дохода проекта производства сейфов оказалось отрицательным (NPV=-$338 тыс.), то можно предположить, что фирма «Гигант» должна отторгнуть этот инвестиционный проект.
Так как результат зависит от величины учётной банковской ставки, имеет смысл поставить вопрос о нахождении величины банковской ставки, при которой ожидаемый чистый дисконтированный доход проекта будет равен нулю. Это будут граничная учётная ставка: если реальная ставка будет меньше, проект следует принять, а если больше – отвергнуть. Расчёт граничной учётной ставки можно провести с помощью средства «Поиск решений». На Рис.3 показаны установка опций и результаты расчёта.
Рис.3. Расчёт граничной учётной ставки.
Итак, граничная учётная ставка равна 8,7%.
Данная задача может быть успешно решена методом статистических испытаний. Для этого необходимо осуществить формализованное описание структуры дерева и его количественных характеристик. Возможный вариант этого заключается в следующем.
Каждой вершине дерева ставится в соответствие таблица вида
| Год/Путь | Инвестиция/Поток | Смещение по строкам | Смещение по столбцам | ||
| p1 | 0 p1 | Смещение по строкам | Смещение по столбцам | ||
| p2 | 0 p1 p2 | Смещение по строкам | Смещение по столбцам | ||
| … | … | … | … | … | |
| pn-1 | n | Смещение по строкам | Смещение по столбцам | ||
| pn | p1 p2 … pn | n | Смещение по строкам | Смещение по столбцам |
Каждая таблица имеет номер в виде «Год/Путь». Формально он не используется, но удобен для описания связей между вершинами. Информационная часть таблицы содержит данные о размере инвестиции или денежном потоке, вероятностях возможных решений, номеров решений и адресов последующих вершин, а точнее таблиц, соответствующих последующим вершинам. Адреса представлены относительными смещениями по строкам и столбцам. Для удобства заполнения таблиц их рационально расположить в соответствии со структурой дерева (Рис.4).
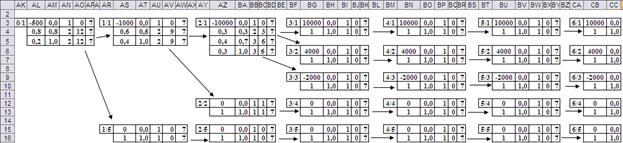
Рис.4. Расположение таблиц вершин дерева.
На нулевом году проекта моделируется принятие одного из двух возможных решений. На последующих годах моделируется одно возможных в соответствии с данными текущей вершины. При этом на каждом году идёт накопление суммы инвестиций или потоков с учётом дисконтирующих коэффициентов. Моделирование возможного пути осуществляется многократно, например 500, результаты (накопленная сумма) усредняются, а затем статистически обрабатываются, как это требует алгоритм метода статистических испытаний. На Рис.5 показана структура таблицы статистических испытаний, а на Рис.6 – ввод формул в таблицу. Часть строк и столбцов скрыта.
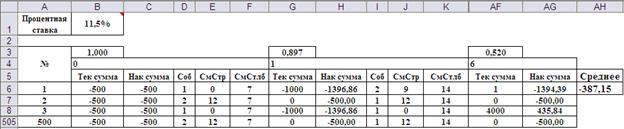
Рис.5. Структура таблицы статистических испытаний.

Рис.6. Ввод формул в таблицу статистических испытаний.
Результаты статистического моделирования соответствуют результатам детерминированного расчёта. Реализация статистического моделирования в данном случае, возможно, покажется более сложной, чем детерминированные расчёты. Однако имеет смысл его осуществить. Приобретённый опыт будет весьма полезен при решении задач, где имеют место вероятностные переходы из одних состояний в другие, например, в системах массового обслуживания.
§
Игрок делает ставку в размере $9,00 и получает возможность четыре раза бросить игровую кость, имеющей на своих гранях числа 1, 2, 3, 4, 5 и 6. Игрок может закончить игру после любого броска, забрав выигрыш, равный удвоенному числу, выпавших во время последнего броска очков. Стоит ли играющему соглашаться на такие условия игры? При положительном ответе разработать стратегию поведения игрока. Попробуем разобраться в описанной игровой ситуации. Прежде всего, представим условия игры в виде таблицы приложения MS Excel на Рис.7.
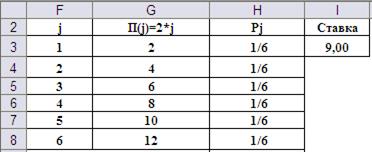
Рис.7. Представление исходных данных в приложении MS Excel.
Очевидно, что если в первом броске выпадет 6 или 5, то игру можно заканчивать, т.к. выигрыш будет превышать сделанную ставку. Правда, во втором случае можно понадеяться на выпадение 6 в последующих бросках. При выпадении в первом броске меньшего, чем 5 числа очков можно, надеясь наудачу в последующих попытках, продолжить игру. С другой стороны, если игрок дошёл до четвёртой попытки, то окончание игры будет безусловным и, возможно, при выпадении малого числа очков, игрок пожалеет, что не прервал игру на более удачных предыдущих попытках.
Решение. Очевидно, что ситуация носит вероятностный характер. Поэтому принятие решения: соглашаться или нет на предложенные условия игры, возможно лишь при оценке среднего выигрыша. Поставленная задача относится к задачам вероятностного динамического программирования. Они решаются в соответствии с алгоритмом обратной прогонки [1-3].
Для функции Беллмана введём обозначение 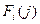 , означающее средний выигрыш на i-ом шаге при условии, что выпало j очков. Очевидно, её нужно вычислять как максимум между текущим выигрышем при выпадении j очков
, означающее средний выигрыш на i-ом шаге при условии, что выпало j очков. Очевидно, её нужно вычислять как максимум между текущим выигрышем при выпадении j очков 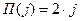 и средним значением функции Беллмана на последующем шаге
и средним значением функции Беллмана на последующем шаге 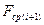 , т.е.
, т.е.
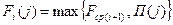
Если всего шагов n, то очевидно, что:
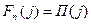 ,
,
т.к. у последнего шага последующих шагов нет. Для формализации и однотипности действий на каждом шаге удобно считать, что 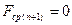 .
.
Итак, алгоритм обратной прогонки.
Шаг 1-ый, i=4. Его результат представлен таблицей, рассчитанной в MS Excel (Рис.8)
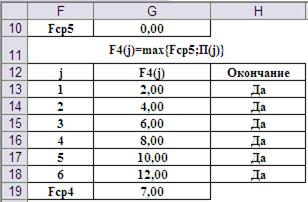
Рис.8. Результат первого шага вычисления функции Беллмана.
Данные были автоматически сформированы при вводе в ячейки рабочего листа формул, представленных на Рис.9.
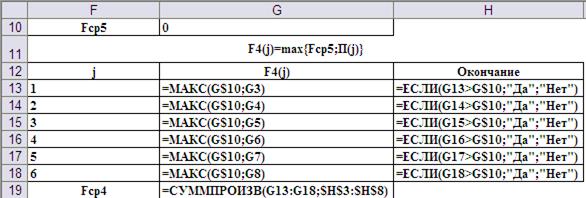
Рис.9. Ввод формул для реализации первого шага.
Шаг 2-ой, i=3. Его результаты и ввод формул для реализации представлены на Рис.10 и Рис.11, соответственно.
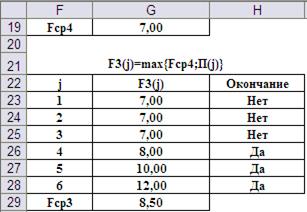
Рис.10. Результат второго шага вычисления функции Беллмана.
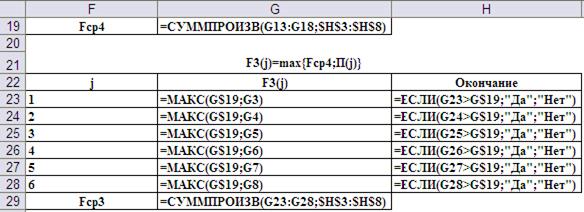
Рис.11. Ввод формул для реализации второго шага.
Выполнение третьего и четвёртого шагов показаны на Рис.12 (результаты) и Рис.13 (формулы).
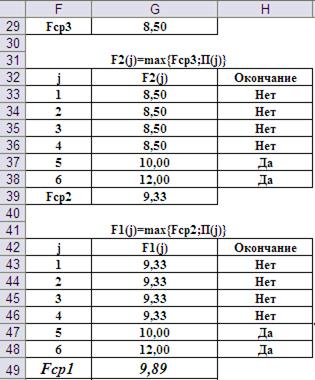
Рис. 12. Результаты расчётов на третьем и четвёртом шагах.
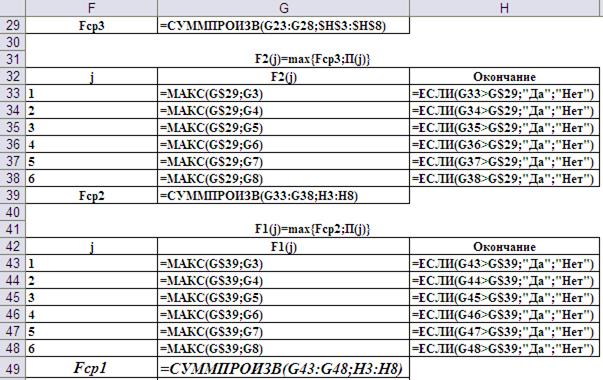
Рис. 13. Ввод формул для выполнения третьего и четвёртого шагов.
Итак, в результате реализации алгоритма обратной прогонки получили ответы на оба поставленных вопроса задачи. Во-первых, т.к. Fcp1=9,89 превышает сделанную ставку, равную 9, то условия игры могут быть приняты. Во-вторых, оптимальная стратегия действий игрока на каждом шаге представлена в третьих столбцах таблиц результатов на каждом шаге. При игре их надо просматривать в прямом, а не в обратном, порядке.
Организация рабочего листа в приложении MS Excel позволяет ответить и ряд других вопросов. Например, нечистые на руку организаторы игрового бизнеса предлагают играть «краплёными» костями с вероятностью выпадения граней, представленных в таблице:
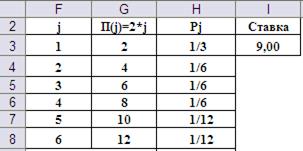
Указанные в таблице вероятностные характеристики игральных костей можно получить за счёт смещения центра тяжести костей.
В этом случае Fcp1=8,35 (Рис.14).
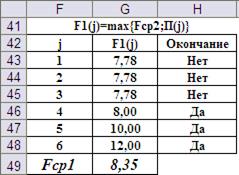
Рис. 14. Результат выполнения четвёртого шага при «краплёных» игральных костях.
Таким образом, ожидаемый выигрыш при оптимальной стратегии меньше, чем сделанная ставка! Принимать условия игры не следует.
Проделанные расчёты можно подкрепить статистическими испытаниями. На Рис.15 показана структура статистической таблицы и результат однократного моделирования при «краплёных» игральных костях.

Рис. 15. Структура таблицы статистических испытаний и результат моделирования при «краплёных» игральных костях.
Таблица для моделирования бросков «краплёных» игральных костей показана на Рис.16. Идеология её построения излагалась в предыдущей лабораторной работе.
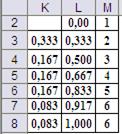
Рис. 16. Таблица для моделирования бросков «краплёных» игральных костей.
Формулы для реализации метода статистических испытаний показаны на Рис.17.

Рис. 17. Ввод формул для реализации метода статистических испытаний.
На Рис.17 показаны формулы только для первого бросания игральной кости. Формулы, моделирующие бросания на следующих шагах, идентичны. Поэтому соответствующие столбцы скрыты.
Простейшие экономические задачи, решаемые методом динамического программирования
На главную страницу
Динамическое программирование
В конец страницы
16.3. ПРОСТЕЙШИЕ ЭКОНОМИЧЕСКИЕ ЗАДАЧИ, РЕШАЕМЫЕ МЕТОДОМ
ДИНАМИЧЕСКОГО ПРОГРАММИРОВАНИЯ
Задача 1 (Задача распределения капиталовложений). Планируется
распределение начальной суммы средств
![]() между
между
n предприятия-
ми
![]() .
.
Предполагается, что выделенные предприятию
![]() в
в
начале планового периода средства ![]() приносят
приносят
доход ![]() .
.
Будем считать, что:
1) доход,
полученный от вложения средств в предприятие ![]() ,
,
не зависит от вложения средств в другие предприятия;
2) доход,
полученный от разных предприятий, выражается в одинаковых единицах;
3) общий
доход равен сумме доходов, полученных от всех средств, вложенных во все
предприятия.
Математическая модель задачи
следующая:

при ограничениях

Опишем задачу в виде модели динамического программирования.
За номер k-го
шага примем номер предприятия, которому выделяются средства
![]() .
.
Уравнениями состояния служат равенства
![]() .
.
Суммарный доход за n шагов составит
 .
.
Уравнения Беллмана имеют вид
![]()
![]() .
.
Пример. Для развития трех
предприятий выделено 5 млн руб. Известна эффективность капитальных вложений в
каждое предприятие, заданная функцией полезности
![]() (i
(i
= 1, 2, 3). Составить оптимальный план распределения средств между
предприятиями, предположив, что оно проводится в целых числах (0, 1, 2, 3, 4 и 5
млн руб.).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Исходные данные задачи
приведены в таблице. Имеем три управляющие переменные
![]() ,
,
![]() ,
,
![]() и
и
четыре параметра состояния ![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Уравнениями состояния служат
равенства:
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Данный процесс является
трехшаговым. Так как на последнем шаге процесс завершается и прибыль на
«последующих» шагах отсутствует, то и
![]() .
.
Запишем уравнение Беллмана для
последнего шага:
![]()
и для всех предыдущих шагов:
 ,
,
![]()
Уравнение Беллмана для любого
шага:
![]() .
.
Расчеты располагаем в двух
таблицах – основной, в которой помещаем результаты условной оптимизации, и
вспомогательной, в которой определяем
![]() и
и
выполняем условную оптимизацию.
В основной таблице входом является
параметр ![]() (0,
(0,
1, 2, 3, 4, 5). Условную оптимизацию начнем с расчета третьего шага.
![]() Таблица
Таблица
16.1 (основная)
| 3-й шаг | 2-й шаг | 1-й шаг | |||
|
|
|
|
|
| |
0 1 2 3 4 5 | 0 3,1 4,7 5,3 5,9 6,5 | 0 1 2 3 4 5 | 0 4,0 7,1 8,7 9,7 10,3 | 0 1 1 1 2 2 | 0 4,1 8,1 11,2 12,8 13,8 | 0 1 1 1 1 1 |
Таблица
16.2 (вспомогательная)
| 2-й шаг | 1-й шаг | ||||||
|
|
|
|
|
|
|
|
|
1 | 0 1 | 1 0 | 0 4,0 | 3,1 0 |
4,0 0 = 4,0 | 0 4,1 | 4,0 0 |
4,1 |
2 | 0 1 2 | 2 1 0 | 0 4,0 5,0 | 4,7 3,1 0 |
4,0 3,1 = 7,1
| 0 4,1 4,5 | 7,1 4,0 0 |
8,1
|
3 | 0 1 2 3 | 3 2 1 0 | 0 4,0 5,0 5,5 | 5,3 4,7 3,1 0 |
4,0 4,7 = 8,7
| 0 4,1 4,5 5,1 | 8,7 7,1 4,0 0 |
11,2
|
4 | 0 1 2 3 4 | 4 3 2 1 0 | 0 4,0 5,0 5,5 6,0 | 5,9 5,3 4,7 3,1 0 |
5,0 4,7 = 9,7
| 0 4,1 4,5 5,1 6,7 | 9,7 8,7 7,1 4,0 0 |
12,8
|
5 | 0 1 2 3 4 5 | 5 4 3 2 1 0 | 0 4,0 5,0 5,5 6,0 8,0 | 6,5 5,9 5,3 4,7 3,1 0 |
5,0 5,3 = 10,3
| 0 4,1 4,5 5,1 6,7 7,0 | 10,3 9,7 8,7 7,1 4,0 0 |
13,8
|
Перейдем
к безусловной оптимизации. Из первого (последнего по порядку действий) шага
условной оптимизации получаем ![]() –
–
максимальный доход. Здесь же получаем
![]() ,
,
т. е. первому предприятию следует выделить 1 млн. руб.
При
![]() из
из
уравнения состояния находим: ![]() .
.
В пятом столбце таблицы 1 находим
![]() .
.
Вычисляем ![]() .
.
Из третьего столбца таблицы 1
получаем ![]() .
.
Итак,
![]() ,
,
![]() ,
,
![]() ;
;
![]() 4,1
4,1
5,0 4,7 = 13,8.
Приведем решение задачи с
использованием алгоритма прямой прогонки.
1. Предположим, что все средства
отданы первому предприятию. Тогда можно записать:
![]() .
.
В этом случае максимальная прибыль
будет получена от вложения всех 5 млн руб. в это предприятие (![]() )
)
и составит ![]() 7,0
7,0
млн руб.
2. Определим оптимальную стратегию
при распределении средств между первым и вторым предприятиями. При этом
![]() .
.
Очевидно, что
![]() .
.
 ;
;
![]() .
.
 ;
;
![]() .
.
 ;
;
![]() .
.
 ;
;
![]() .
.
 ;
;
![]() .
.
В этом случае максимальная прибыль
будет получена от вложения 1 млн. руб. во второе предприятие (![]() )
)
и 4 млн руб. (![]() 4)
4)
в первое предприятие и составит
![]() млн
млн
руб.
3. Определим оптимальную стратегию
при распределении денежных средств между третьим и первыми двумя предприятиями.
![]() .
.
На третьем, последнем, шаге
достаточно найти ![]() .
.
 ;
;
![]() .
.
Таким образом, максимальный доход
при распределении 5 млн руб. между тремя предприятиями составит
![]() млн
млн
руб. При этом третьему предприятию нужно выделить 2 млн руб. (![]() ).
).
Тогда на долю первых двух
предприятий остается
![]() млн
млн
руб.
Из второго шага находим![]() млн
млн
руб. Эта прибыль достигается, если второму предприятию выделить 2 млн руб. (![]() ).
).
Тогда на долю первого предприятия
остается
![]() млн
млн
руб. (![]() ).
).
Таким образом, оптимальный план
распределения капиталовложений представлен как
Х* = (1, 2 ,2).
При таком варианте распределения
средств будет получен максимальный доход:
![]() 4,1
4,1
5,0 4,7 = 13,8 (млн руб.).
Ответ: Х* = (1, 2 ,2),
![]() 13,8.
13,8.
Задача 2 (Задача календарного
планирования трудовых ресурсов). Предпринимателю необходимо составить план
регулирования численности рабочих на последующие пять недель. Он оценивает
минимальные потребности в рабочей силе
![]() на
на
каждую из пяти недель следующим образом: 5, 7, 8, 4 и 6 рабочих для i = 1, 2, 3, 4 и 5 соответственно. Предприниматель
имеет возможность регулировать количество имеющихся в наличии рабочих путем
найма и увольнения. Пусть ![]() –
–
количество рабочих, имеющихся в наличии на j-й
неделе. Определим ![]() как
как
величину убытков, связанных с тем, что
![]() превышает
превышает
заданное значение ![]() ,
,
а ![]() –
–
как величину накладных расходов по найму новых рабочих
![]() .
.
Необходимо составить оптимальный план регулирования численности рабочих
для 5-недельного периода планирования при условии, что исходное количество
![]() рабочих,
рабочих,
имеющихся в наличии к началу первой недели, составляет пять человек. Опишем
задачу в виде модели динамического программирования.
Этап
j ставится в соответствие j-й
неделе. Состояние![]() на
на
этапе j выражает количество рабочих, имеющихся
к концу этапа j – 1. Вариантырешения
![]() описываются
описываются
количеством рабочих, имеющихся на этапе j.
Обозначим через ![]() минимальную
минимальную
величину расходов, осуществленных в течение периодов времени (недель)
![]() ,
,
при заданном ![]() .
.
Рекуррентное соотношение записывается в следующем виде:
![]()
![]() ,
,
j = 4, 3, 2, 1.
Задача 3 (Задача о загрузке,
или задача о рюкзаке (ранце)). Самолет загружается предметами n различных типов. Каждый предмет типа i имеет вес
![]() и
и
стоимость ![]() .
.
Максимальная грузоподъемность самолета равна W.
Требуется определить максимальную стоимость груза, вес которого не должен
превышать максимальной грузоподъемности самолета.
Обозначим количество предметов
типа i через
![]() .
.
Составим математическую модель задачи

при ограничениях

Каждый из трех основных элементов модели динамического программирования
определяется следующим образом.
Этап j
ставится в соответствие типу j, ![]() .
.
Состояние ![]() на
на
этапе j выражает суммарный вес предметов,
решения о погрузке которых приняты на этапах
![]() ;
;
при этом ![]() и
и
![]() при
при
![]() .
.
Варианты решения ![]() на
на
этапе j описываются количеством предметов
типа j. Значение
![]() заключено
заключено
в пределах от нуля до ![]() .
.
Пусть ![]() –
–
максимальная суммарная стоимость предметов, решения о погрузке которых приняты
на этапах ![]() при
при
заданном состоянии ![]() .
.
Рекуррентное соотношение (для процедуры обратной прогонки) имеет следующий вид:
![]()
![]()
Назад К началу страницы Вперед


 меньше 0
С сегодняшнего дня это сообщение в квике. Вчера всё было нормально, можно было наращивать позу в 2а раза больше. Я один такой красивый?")

